Türkiye Yapay Zeka İnisiyatifi
Yerli yapay zeka girişimlerini haritalandıran, LLM odaklı etki programları (Başlat LLM gibi) yürüten ve ekosistemi global standartlarla buluşturan ana merkez. Girişimcilik ekosistemi için en güvenilir referans noktası.
- Yapay zeka girişimi haritası
- LLM hızlandırma programları
- Sektörel ağ ve iş birliği
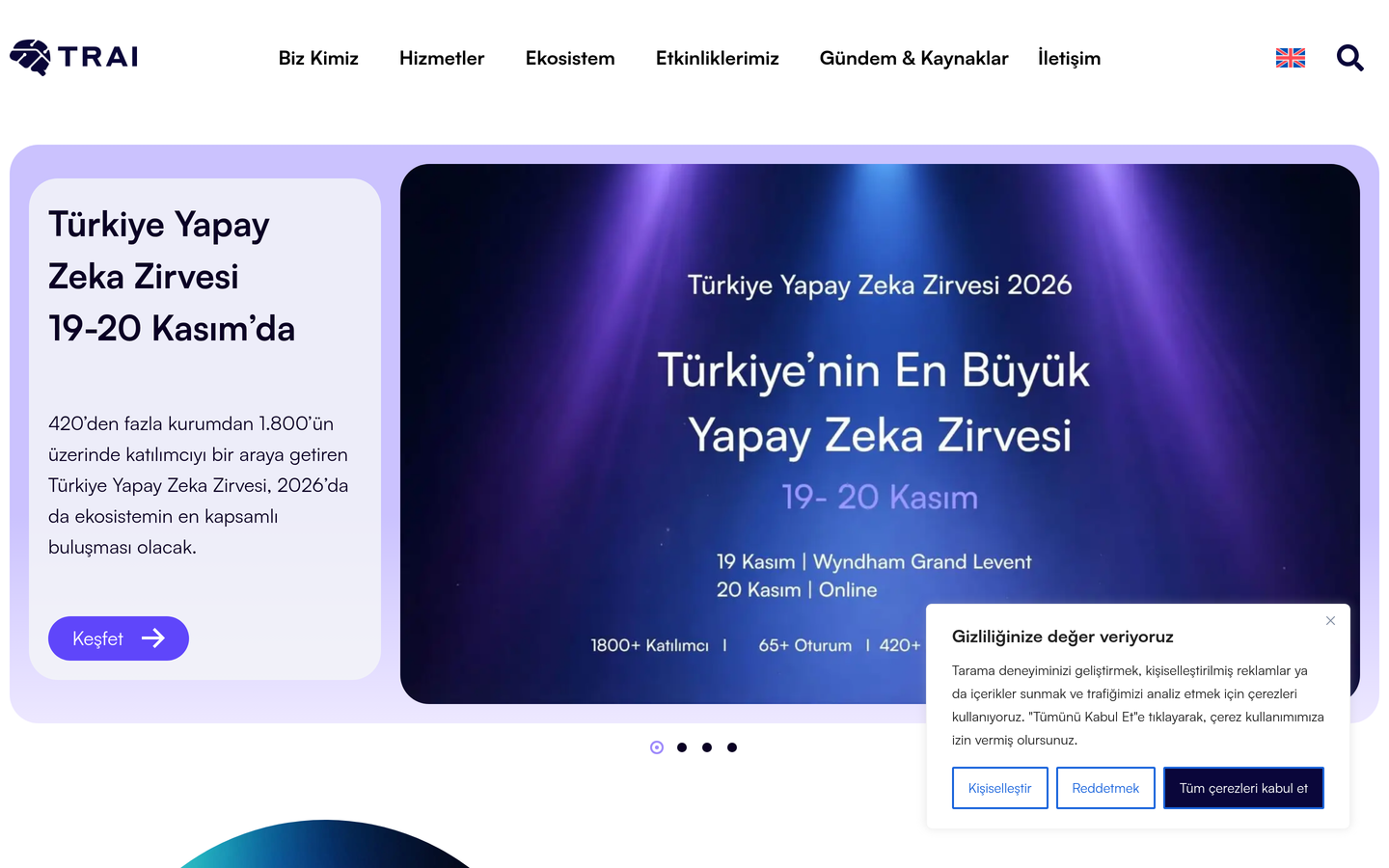
Türkiye Yapay Zeka İnisiyatifi, akademik tasarım denetiminde 63/100 puan alarak bağımsız denetimden geçti. En güçlü yönleri akıcılık (94) ve görsel kararlılık (93); görece geliştirilebilir alanları estetik (34) ve etkileşim tasarımı (42).
Türkiye Yapay Zeka İnisiyatifi, tarafından tasarlanan bu Büyük Dil Modelleri (LLM) platformu olarak 63/100 puan ve "Güçlü Temel" sertifikasyonuyla değerlendirilmiştir. Türkiye Yapay Zeka İnisiyatifi, dijital platformlar arasında gelişim potansiyeli yüksek bir konumda yer almaktadır. WCAG 2.1 erişilebilirlik kriterleri ve Lighthouse performans metrikleri temel uyumluluğu sağlarken, kullanıcıların uzun vadeli memnuniyetini artıracak derinlikli iyileştirmeler için net fırsatlar mevcuttur.
Tasarım Denetimi
Hasler-Süsstrunk renk teorisi, Gestalt ilkeleri ve Fitts Yasası ile hesaplamalı analiz.

Mavi güvenilirlik, otorite ve sakinliği kodlar. B2B ve kurumsal kimlikte dünya genelinde en yaygın tercih edilen tonlamadır; bilinçsiz güven oluşturma gücü yüksektir. (Birren, 1969)
WordPress CMS üzerine kurulu. Plugin ve tema ekosistemiyle geliştirilmiş.
"Dengeli soğuk tonlar profesyonellik ve güvenilirlik mesajı iletiyor; kurumsal algı başarılı."
Karşılaştır & İzle
Sektör ortalamasıyla karşılaştırma ve tarihsel skor değişimi.
Büyük Dil Modelleri (LLM)
Türkiye Yapay Zeka İnisiyatifi bu kategoride 5 puan altında — sektör ortalaması 68/100. En iyi %79 dilimindedir.
Benzer Skorlu Siteler
Ölçüm ortamı hakkında: Teknik performans için öncelik CrUX (Chrome User Experience Report — gerçek kullanıcıların canlı saha verisi); CrUX verisi yoksa Lighthouse(kontrollü lab/test ortamı) kullanılır. Bu iki ortam farklı koşullarda ölçtüğü için bazı metrikler birbirinden ayrışabilir — örneğin sunucu yanıtı (TTFB) lab'da hızlı görünürken, gerçek kullanıcıların içerik boyaması (LCP) ağ ve cihaz koşulları nedeniyle daha yavaş çıkabilir. Her iki değer de doğrudur; yalnızca farklı pencerelerden bakar.